Program-Compilation-and-ELF-Format-Lab-1
实验目的
1、熟悉 C 代码的编译过程与 ELF 文件格式。
2、初步学习使用 Linux 平台的二进制分析工具。
实验原理
C 代码的编译过程与 ELF 文件格式。
实验环境
Ubuntu 16.04 虚拟机。
初始设置
使用下述命令进行系统更新:
$ cd /home/binary && rm -f auto-update.sh
&& wget -q --no-check-certificate
https://practicalbinaryanalysis.com/patch/auto-update.sh
&& chmod 755 auto-update.sh && ./auto-update.sh

设置时间戳:
打开"显示隐藏文件"选项,打开.bashrc文件,在最后加上:
export PS1='\D{[%F %T]} ${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$'

使用 source /.bashrc 使其生效:

哦对,还要改时区:
实验任务
Task 1:C 编译过程
预处理阶段
进入到 /code/chapter1 目录下,输入 gcc -E -P compilation_example.c,输出结果为:

...
int
main(int argc, char *argv[]) {
printf("%s", "Hello, world!\n");
return 0;
}
Q:对比原始代码,当前 main 函数有什么变化?
A:printf语句中的内容从参数(FORMAT_STRING ,MESSAGE)变成了这两个参数所指向的具体的内容("%s", "Hello,world!n")。
编译阶段
输入 gcc -S compilation_example.c:

输出结果为:
.file "compilation_example.c"
.section .rodata
.LC0:
.string "Hello, world!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl %edi, -4(%rbp)
movq %rsi, -16(%rbp)
movl $.LC0, %edi
call puts
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609"
.section .note.GNU-stack,"",@progbits
汇编阶段
输入:gcc -c compilation_example.c:

Q:当前生成的文件类型是什么?这个文件是否可以执行?为什么?
A:生成的文件是compilation_example.o,类型为目标文件;不可以直接执行,因为它还没有链接到其他的目标文件,所以它的代码段中有一些未定义的符号。
链接阶段
输入: gcc compilation_example.c, file a.out,./a.out

Q:当前生成的文件类型是什么?
A:生成的文件是a.out,类型为可执行文件。
Task 2:符号与剥离的二进制文件
分别使用 nm 和 readelf 输出 a.out 二进制文件中的符号。
nm输出结果:
...
0000000000400526 T main
U puts@@GLIBC_2.2.5
00000000004004a0 t register_tm_clones
0000000000400430 T _start
0000000000601038 D __TMC_END__

readelf中参数 -s 意为显示符号表,readelf输出结果:
...
__libc_start_main@@GLIBC_
54: 0000000000601028 0 NOTYPE GLOBAL DEFAULT 25 __data_start
55: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
56: 0000000000601030 0 OBJECT GLOBAL HIDDEN 25 __dso_handle
57: 00000000004005d0 4 OBJECT GLOBAL DEFAULT 16 _IO_stdin_used
58: 0000000000400550 101 FUNC GLOBAL DEFAULT 14 __libc_csu_init
59: 0000000000601040 0 NOTYPE GLOBAL DEFAULT 26 _end
60: 0000000000400430 42 FUNC GLOBAL DEFAULT 14 _start
61: 0000000000601038 0 NOTYPE GLOBAL DEFAULT 26 __bss_start
62: 0000000000400526 32 FUNC GLOBAL DEFAULT 14 main
63: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _Jv_RegisterClasses
64: 0000000000601038 0 OBJECT GLOBAL HIDDEN 25 __TMC_END__
65: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_registerTMCloneTable
66: 00000000004003c8 0 FUNC GLOBAL DEFAULT 11 _init

Q:main 函数加载到内存时的驻留地址是什么?
A:驻留地址是0000000000400526。
--strip-all参数告诉strip移除文件中的所有符号信息。使用 strip 命令进行剥离,对于 a.out 再次执行 file 和 readelf -s:
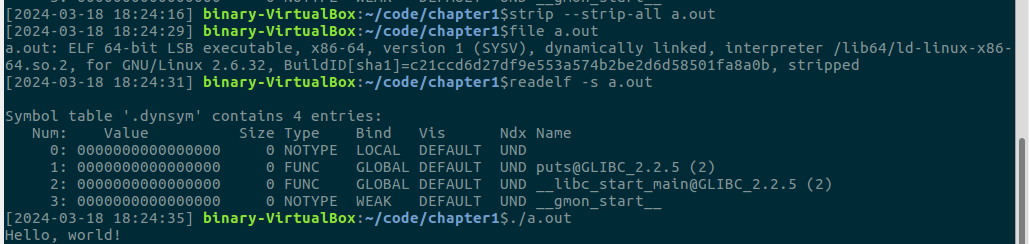
Q:此时对于 a.out 再次执行 file 和 readelf -s,结果有什么变化?运行 a.out,其功能有何变化?
A:使用file命令时发现出现了stripped状态;使用readlf -s命令时发现符号表".symtab"被全部删除。运行a.out,发现依然输出"Hello, world!",功能无变化。
Task 3:反汇编二进制文件
-sj .rodata参数告诉objdump命令仅显示'.rodata'(只读数据)段的内容。输入objdump -sj .rodata compilation_example.o:

Q:有哪些只读数据存储在.rodata 段中?
A:.rodata 段内容:0000 48656c6c 6f2c2077 6f726c64 2100 Hello, world!. 即只有输出内容存储在.rodata 段中。
-h参数告诉readelf显示ELF文件头的信息。输入readelf -h compilation_example.o:
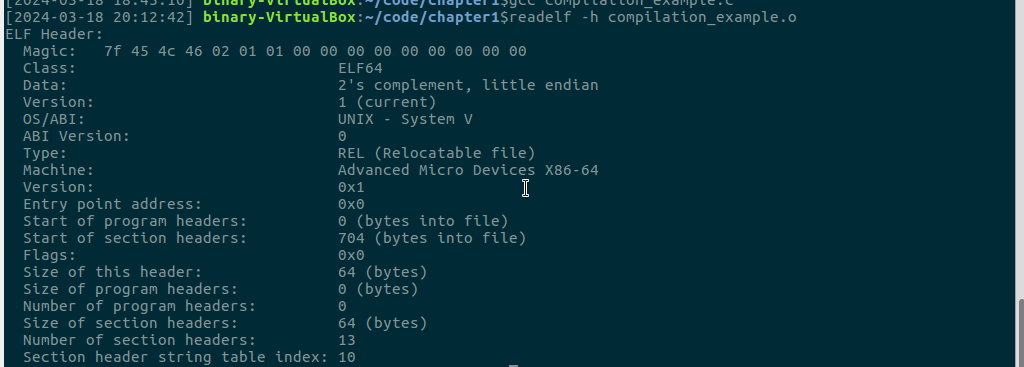
-d 参数告诉objdump显示反汇编目标文件的所有代码段。输入objdump -d compilation_example.o:
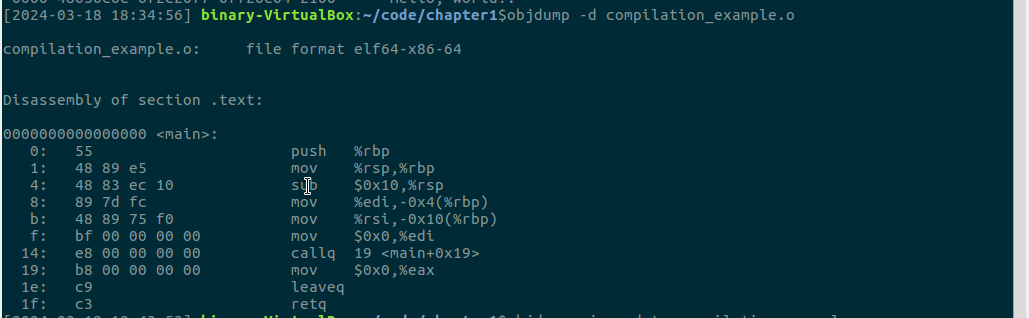
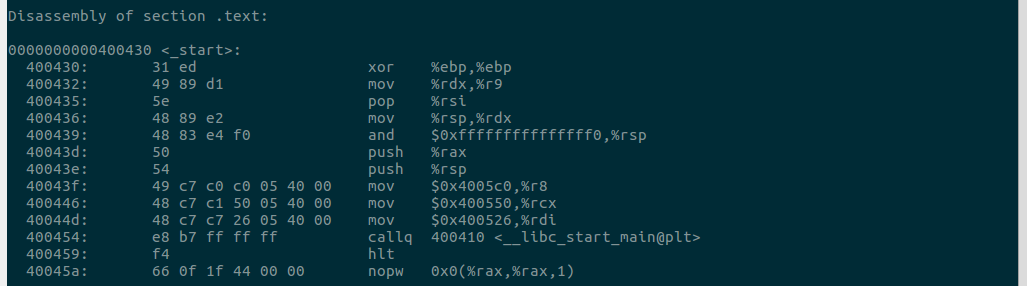
反汇编一个完整的可执行二进制文件 a.out:
1、gcc compilation_example.c 指令重新生成 a.out 文件。
2、objdump -d a.out 指令反汇编 a.out。

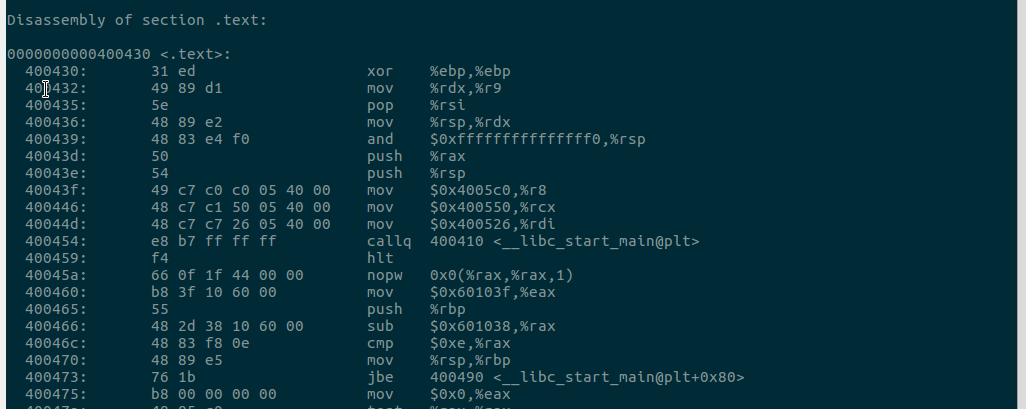
3、strip --strip-all a.out 指令剥离基本符号信息
4、objdump -d a.out 指令反汇编被剥离的 a.out。

Q:对比带符号的二进制文件和已剥离的二进制文件的反汇编结果,你有什么发现?(在.text 方面)
A:在.text段,两者的机器指令是相同的。这是因为剥离符号信息并不会改变程序的执行逻辑。但是变量名有所区别,
思考题
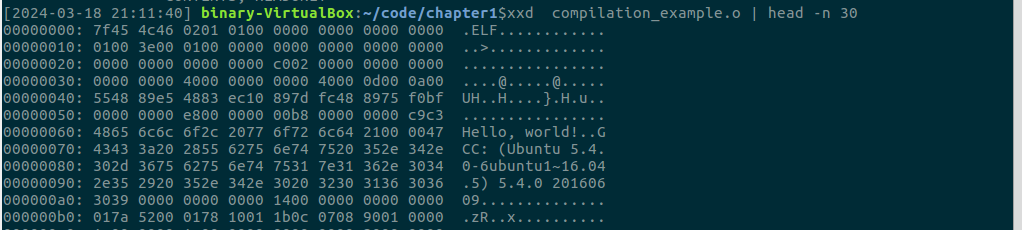
Q:你能识别 ELF 头部中字段代表的含义吗?尝试在 xxd 输出中找到所有 ELF 头部的字段,并解析这些字段内容的含义。
A:输入xxd compilation_example.o | head -n 30 查看前30行内容。我们可以按照 ELF 格式规范解析出各个字段的内容。以下是解析过程:
魔数(Magic):7f45 4c46:ELF 文件的魔数,表示这是一个 ELF 文件。
类别(Class):02:表示这是一个 64 位的 ELF 文件。
数据编码(Data):01:表示这是一个小端序(Little Endian)的 ELF 文件。
版本(Version):01:表示当前版本为 1。
操作系统/ABI(OS/ABI):00:表示 System V ABI。
ABI 版本(ABI Version):00:表示 ABI 版本为 0。
填充字节(Padding):0000 0000 0000 0000:7 个字节的填充,用于对齐。
文件类型(Type):0100:表示这是一个可重定位文件(Relocatable File)。
机器架构(Machine):3e00:表示这是一个 AMD x86-64 架构。
版本(Version):0100 0000:表示当前版本为 1。
入口点地址(Entry point address):0000 0000 0000 0000:表示入口点地址为 0。
程序头部表的文件偏移量(Start of program headers):0000 0000 0000 0000:表示程序头部表的偏移量为 0。
节头部表的文件偏移量(Start of section headers):c002 0000 0000 0000:表示节头部表的偏移量为 0x2c0。
标志(Flags):0000 0000:表示没有特殊标志。
头部大小(Size of this header):4000:表示 ELF 头部的大小为 64 字节。
程序头部表中每个条目的大小(Size of program headers):0000:表示程序头部表中每个条目的大小为 0。
程序头部表中条目的数量(Number of program headers):0000:表示程序头部表中没有条目。
节头部表中每个条目的大小(Size of section headers):4000:表示节头部表中每个条目的大小为 64 字节。
节头部表中条目的数量(Number of section headers):0d00:表示节头部表中有 13 个条目。
节头部字符串表在节头部表中的索引(Section header string table index):0a00:表示节头部字符串表在节头部表中的索引为 10。
之后的内容不属于 ELF 头部字段,而是程序的机器码和其他信息。